

In my work, I deal a lot with novel technical solutions/software. But unfortunately, it’s not always that they can boast with extensive information I might need. This article fulfills one such gap linked to my recent task when I was supposed to turn two popular DBMS (PostgreSQL и MongoDB) into event streams and send those CDC events into the Kafka cluster using Debezium. So, while this article is a review, it is based on my practical experience, and I hope it can help others.
What is CDC and Debezium?
Debezium is a CDC (Capture Data Change) streamer, or, more precisely, it is a set of connectors for various database families compatible with the Apache Kafka Connect framework.
Debezium is an Open Source project licensed under Apache License v2.0 and sponsored by Red Hat. It was launched in 2016 and currently supports the following DBMSs: MySQL, PostgreSQL, MongoDB, SQL Server, Oracle, and IBM Db2. In addition, there are Cassandra and Vitess connectors available; however, at the moment, they have the “incubating” status and are “subject to changes that may not always be backward compatible.”
The main advantage of CDC compared to the classic approach (when an application directly reads data from the database) is the low-latency, reliable, and fault-tolerant streaming of row-level data changes. The last two points are achieved by using the Kafka cluster as storage for CDC events.
Another advantage is the single, unified model for storing events, so the application does not have to “worry” about the operating nuances of various DBMS.
Finally, the message broker opens the door to horizontal scaling of applications that capture changes in data. At the same time, the impact on the data source is minimal since data is streamed not from the DBMS but Kafka cluster.
Debezium architecture
Debezium operates according to the following basic scheme:
DBMS (as a data source) → Kafka Connect connector → Apache Kafka → consumer
Here is the relevant diagram from the project’s website:
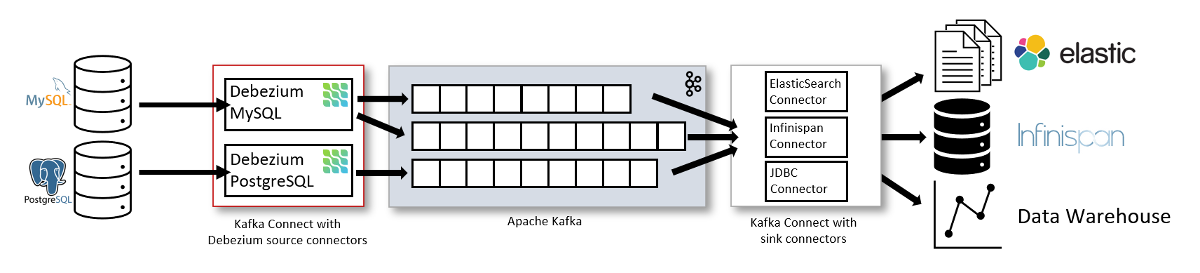
However, it is not perfect as it suggests that there is no alternative to sink connectors.
In reality, it is a different story: filling your Data Lake (the last element in the diagram above) is not the only way to use Debezium. Your applications can use events sent to Apache Kafka to perform various tasks, such as:
- deleting old cache data;
- sending notifications;
- updating search indexes;
- keeping audit logs;
- …
If you have a Java application and don’t need/can’t use a Kafka cluster, you can take advantage of the embedded connector. In this case, you can drop the extra infrastructure (in the form of a connector and Kafka). However, this solution has been deprecated starting with version 1.1 and is no longer recommended for use (it may be removed in future releases).
In this article, we will solely examine the fault-tolerant and scalable architecture recommended by developers.
Configuring the connector
To start monitoring data changes, we will need:
- the data source. It can be the MySQL 5.7+, PostgreSQL 9.6+, MongoDB 3.2+ database (you can find the complete list of supported DBs and their versions here);
- the Apache Kafka cluster;
- the instance of Kafka Connect (1.x or 2.x);
- the configured Debezium connector.
The first two points (i.e., installing the DBMS and Apache Kafka) are beyond the scope of this article. For those who would like to “play” with this tool in sandbox mode, there is a ready-made docker-compose.yaml file in the official repository.
We, for our part, will focus on the last two points.
0. Kafka Connect
From now on, all examples are based on the Docker image provided by Debezium developers. It contains all the necessary plugins (connectors) and provides for the configuration of Kafka Connect using environment variables.
If you plan to use Confluent’s distribution of Kafka Connect, you will have to copy plugins of all the necessary connectors to the directory specified in plugin.path (or set via the CLASSPATH environment variable). The Kafka Connect worker and connectors are configured using the config files that are passed as arguments to the command that launches a worker (learn more in the documentation).
The process of configuring Debezium and the connector is carried out in two stages. Let’s look at each one of them.
1. Configuring the Kafka Connect framework
You must set some additional parameters in the Kafka Connect so it can stream data to the Apache Kafka cluster:
- cluster connection settings,
- topic names where the configuration of the connector will be stored,
- the name of the group in which the connector is running (in a distributed mode).
The official Debezium Docker image allows you to configure all the parameters by setting environment variables — let’s take advantage of it! Download the image:
docker pull debezium/connectBelow is the minimal set of environment variables required for running a connector:
BOOTSTRAP_SERVERS=kafka-1:9092,kafka-2:9092,kafka-3:9092— the list of Kafka servers for establishing the initial connection to the cluster;OFFSET_STORAGE_TOPIC=connector-offsets— sets the topic to commit offsets to;CONNECT_STATUS_STORAGE_TOPIC=connector-status— the name of the topic where the state for connectors and their tasks is stored;CONFIG_STORAGE_TOPIC=connector-config— the name of the topic to store connector and task configuration data;GROUP_ID=1— the identifier of the worker group where the connector’s task can be performed; this parameter is needed for the distributed mode.
Run the container and set the above variables:
docker run \
-e BOOTSTRAP_SERVERS='kafka-1:9092,kafka-2:9092,kafka-3:9092' \
-e GROUP_ID=1 \
-e CONFIG_STORAGE_TOPIC=my_connect_configs \
-e OFFSET_STORAGE_TOPIC=my_connect_offsets \
-e STATUS_STORAGE_TOPIC=my_connect_statuses debezium/connect:1.2
A few words about Avro
By default, Debezium writes the JSON-formatted data. This method is acceptable for sandboxes and small volumes of data but can be a problem in high-load databases. Avro is an excellent alternative to the JSON converter. It can serialize the record keys and values into binary form, which reduces the load on the I/O Apache Kafka subsystem.
However, you have to deploy a separate schema-registry (for storing schemas) to use Avro. In this case, set the following converter environment variables:
name: CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL
value: http://kafka-registry-01:8081/
name: CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL
value: http://kafka-registry-01:8081/
name: VALUE_CONVERTER
value: io.confluent.connect.avro.AvroConverterDetails on using Avro and setting up schema registry are beyond the scope of our story. For clarity, we will settle on the JSON format in this article.
2. Configuring the connector
Now it is time to configure the connector that will read data from the source.
Let’s configure connectors for DBMS (PostgreSQL and MongoDB) as an example since I have hands-on experience with them. There are minor but significant (in some cases) differences in the process.
The configuration has a JSON format and is uploaded to Kafka Connect via a POST request.
2.1. PostgreSQL
An example configuration of the PostgreSQL connector:
{
"name": "pg-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"plugin.name": "pgoutput",
"database.hostname": "127.0.0.1",
"database.port": "5432",
"database.user": "debezium",
"database.password": "definitelynotpassword",
"database.dbname" : "dbname",
"database.server.name": "pg-dev",
"table.include.list": "public.(.*)",
"heartbeat.interval.ms": "5000",
"slot.name": "dbname_debezium",
"publication.name": "dbname_publication",
"transforms": "AddPrefix",
"transforms.AddPrefix.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.AddPrefix.regex": "pg-dev.public.(.*)",
"transforms.AddPrefix.replacement": "data.cdc.dbname"
}
}With the above settings, the connector operates as follows:
- Once started, it connects to the specified database and switches to the initial snapshot mode. In this mode, it sends the initial set of data obtained using a typical
SELECT * FROM table_namequery to Kafka. - After the initialization is complete, the connector switches to the change data capture mode using PostgreSQL’s WAL files as a source.
A brief description of the properties in use:
nameis the name of the connector that uses the configuration above; this name is later used for interacting with the connector (i.e., viewing the status/restarting/updating the configuration) via the Kafka Connect REST API;connector.classis the DBMS connector class to be used by the connector being configured;plugin.nameis the name of the plugin for the logical decoding of WAL data. Thewal2json,decoderbuffs, andpgoutputplugins are available for selection. The first two require the installation of the appropriate DBMS extensions;pgoutputfor PostgreSQL (version 10+) does not require additional actions;database.*— options for connecting to the database, wheredatabase.server.nameis the name of the PostgreSQL instance used to generate the topic name in the Kafka cluster;table.include.listis the list of tables to track changes in; it has theschema.table_nameformat and cannot be used together with thetable.exclude.list;heartbeat.interval.ms— the interval (in milliseconds) at which the connector sends heartbeat messages to a Kafka topic;heartbeat.action.queryis a query that the connector executes on the source database at each heartbeat message (this option was introduced in version 1.1);slot.nameis the name of the PostgreSQL logical decoding slot. The server streams events to the Debezium connector using this slot;publication.nameis the name of the PostgreSQL publication that the connector uses. If it doesn’t exist, Debezium will attempt to create it. The connector will fail with an error if the connector user does not have the necessary privileges (thus, you better create the publication as a superuser before starting the connector for the first time).transformsdefines the way the name of the target topic is changed:transforms.AddPrefix.typespecifies that regular expressions are used;transforms.AddPrefix.regexspecifies the mask used to rename the target topic;transforms.AddPrefix.replacementcontains the replacing string.
A few notes on heartbeat and transforms
By default, the connector writes data to Kafka about each committed transaction, while its LSN (Log Sequence Number) is written to the offset service topic. But what if the connector is configured to monitor only a part of the database (where updates are pretty rare)?
- In this case, the connector will not find any transaction commits related to the monitored tables in WAL files.
- Thus, it will not update its current position in either the topic or the replication slot.
- This, in turn, would “keep” WAL files on the disk and eat up the disk space.
And that’s when heartbeat.interval.ms and heartbeat.action.query parameters might come in handy. These two options allow you to make a query to some table in response to a heartbeat message. This way, the connector can send the current LSN to the database, allowing the DBMS to delete WAL files that are no longer needed. You can learn more about these two options in the documentation.
transforms is another parameter that merits close attention (even if it is more about convenience and overall beauty).
By default, Debezium uses the following policy for naming topics — serverName.schemaName.tableName. However, it is not suitable for all cases. The family of transforms options allows you to use regular expressions to define a list of tables and route events from them to a specific topic.
In our configuration, all CDC events related to the monitored database will end up in the topic called data.cdc.dbname. Otherwise (without such parameters), Debezium would create a topic of the following form: pg-dev.public.<table_name> for each table.
Connector limitations
At the end of this section, I would like to say a few words about the PostgreSQL connector limitations/peculiarities:
- The connector relies on PostgreSQL’s logical decoding feature. Therefore, it does not capture DDL changes and is unable to reflect these events in topics.
- Replication slots mean that the connector can only be connected to the primary database instance.
- If the connector user has read-only access, you will need to manually create the replication slot and the database publication.
Applying the configuration
Let’s upload our configuration to the connector:
curl -i -X POST -H "Accept:application/json" \
-H "Content-Type:application/json" \ http://localhost:8083/connectors/ \
-d @pg-con.jsonCheck that the upload is successful and the connector is running:
$ curl -i http://localhost:8083/connectors/pg-connector/status
HTTP/1.1 200 OK
Date: Thu, 17 Sep 2020 20:19:40 GMT
Content-Type: application/json
Content-Length: 175
Server: Jetty(9.4.20.v20190813)
{"name":"pg-connector","connector":{"state":"RUNNING","worker_id":"172.24.0.5:8083"},"tasks":[{"id":0,"state":"RUNNING","worker_id":"172.24.0.5:8083"}],"type":"source"}Great! It is properly configured and ready to stream events. Now let’s start the fake consumer, connect it to the Kafka server, and then alter an entry in the database:
$ kafka/bin/kafka-console-consumer.sh \
--bootstrap-server kafka:9092 \
--from-beginning \
--property print.key=true \
--topic data.cdc.dbname
postgres=# insert into customers (id, first_name, last_name, email) values (1005, 'foo', 'bar', 'foo@bar.com');
INSERT 0 1
postgres=# update customers set first_name = 'egg' where id = 1005;
UPDATE 1In this case, our topic will take the following form: A lengthy JSON output containing our changes.
In both cases, records contain the key (PK) and the changes themselves (the contents of the record before and after the changes).
- In the case of
INSERT, thepayload.beforeis null, and thepayload.afteris the string that was inserted. - In the case of
UPDATE, thepayload.beforecontains the old string, while thepayload.aftercontains the new string.
2.2 MongoDB
The MongoDB connector leverages the standard replication mechanism of MongoDB by reading the oplog (operation log) of the primary server of the replica set.
Similar to PgSQL, the connector performs a snapshot of the primary’s databases at the first launch. After copying is complete, the connector switches to the oplog reading mode.
Here is an example of the configuration:
{
"name": "mp-k8s-mongo-connector",
"config": {
"connector.class": "io.debezium.connector.mongodb.MongoDbConnector",
"tasks.max": "1",
"mongodb.hosts": "MainRepSet/mongo:27017",
"mongodb.name": "mongo",
"mongodb.user": "debezium",
"mongodb.password": "dbname",
"database.whitelist": "db_1,db_2",
"transforms": "AddPrefix",
"transforms.AddPrefix.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.AddPrefix.regex": "mongo.([a-zA-Z_0-9]*).([a-zA-Z_0-9]*)",
"transforms.AddPrefix.replacement": "data.cdc.mongo_$1"
}
}As you can see, there are no new parameters as compared to the previous example. However, the number of parameters for connecting to the database and setting prefixes is lower.
This time, the transforms family of options transforms (you guessed that right!) the scheme for setting the name of the target topic from <server_name>.<db_name>.<collection_name> to data.cdc.mongo_<db_name>.
Fault-tolerance
The problem of fault tolerance and high availability is now more acute than ever — especially in data and transactions. Capturing data changes is a large part of this problem. Let’s examine what can go wrong and what would happen to Debezium in each case.
There are three types of failures:
- The failure of Kafka Connect. If Connect runs in a distributed mode, then all workers must have the same
group.id. In this case, if one of the workers fails, the connector would restart on another worker and continue reading from the last committed position in the Kafka topic. - Loss of connectivity with the Kafka cluster. The connector stops reading at the position that it fails to send to Kafka and periodically tries to resend it until the attempt is successful.
- Unavailability of the data source. The connector will attempt to reconnect to the source as prescribed by the configuration. By default, the connector makes 16 attempts using the exponential backoff algorithm. After the 16th failed attempt, the task will be marked as failed. In this case, you will have to restart it manually via Kafka Connect’s REST interface.
- PostgreSQL. Data will not be lost because replication slots prevent the deletion of the unread WAL files. However, there is a downside as well. In case of prolonged loss of connectivity between the connector and the DBMS, the disk space may run out, and that will lead to total DBMS failure.
- MySQL. In this case, the DBMS may purge binlog files before connectivity is restored. This will cause the connector to switch to the failed state. You will have to restart it in the initial snapshot mode for restoring its regular operation and resuming reading from binlogs.
- MongoDB. As stated in the documentation, the connector’s behavior in the case of deleting log/oplog files (thus, the connector cannot continue reading from the position where it left off) is the same for all DBMSs. In this case, the connector switches to the failed state and needs to be restarted in the initial snapshot mode.
However, there are exceptions. If the connector is stopped (or cannot connect to the MongoDB instance) for a long time, and the oplog is purged during that time, the connector resumes streaming from the first available position as if nothing happened. In this case, part of the data will not get to Kafka.
Conclusion
Debezium is my first and generally positive experience in the world of CDC systems. I like its support for the most popular DBMS, simple configuration, clustering capabilities, and active community. If you are interested and would like to make things more practical, I recommend these Kafka Connect and Debezium guides.
Compared to the JDBC connector for Kafka Connect, the main advantage of Debezium is that it reads changes directly from DBMS logs and, thus, streams them with minimal delay. The JDBC connector (bundled with Kafka Connect) queries the monitored table at fixed intervals and, for the same reason, cannot generate events on data deletion (how can you query data that does not exist?).
The following tools and solutions (in addition to Debezium) might be helpful for solving similar tasks — take a look at them:
- JDBC Connector Kafka Connect;
- Several MySQL solutions;
- Oracle GoldenGate, but that is an entirely different “league.”

Comments