

As you know, we have discussed some of our failure stories before. However, this article is somewhat unique, as it launches a special series of publications dedicated to disasters that emerged due to different reasons. After all, incidents, their causes, and consequences are an essential part of our life, and exploring this “dark side” of Ops is as fascinating as everything else. Moreover, their impact on our everyday life is growing, so the lessons they provide can and should be learned. Apart from that, our readers have repeatedly asked us to publish more stories like this, so here we go!
The first story shows why inadequate communication is harmful and what consequences it can lead to. As for us, we highly value and support the culture of open, well-established, and (when necessary) closest interaction. However, even the best of us are prone to errors. Today’s story vividly shows how a mostly organizational problem can hit a weak spot in the technical specificities of the project, leading to an unexpected incident.
Let’s move on to the technical side…
The initial task
The ClickHouse cluster was composed of four servers with large HDDs. It had two shards, each containing two replicas. It also had several tables (within the single database), including two main tables for storing raw and processed data.
The cluster was used for storing various business analytics (and it had coped with this task perfectly). However, the development team sometimes processes much larger samples, uses complex aggregations, and needs to get the results quickly. The cluster did not meet these requirements: it was too slow, could not cope well with a large load, and could not process the newly received data in time.
That is why we decided to deploy a second ClickHouse cluster that would act as a “rapid buffer.” It would contain the same set of data but for a much shorter period. The development team was responsible for inserting and processing the data. All we had to do is to deploy the cluster. We decided to use the two NVMe-based servers, each containing two shards with a replica. We did not need the redundancy and protection against data loss since we had the same data in the primary cluster. Downtime (in the case of replica failure) was not the problem either: we could carry out recovery in a planned mode.
The implementation
Well, we got the resources and proceeded with setting up the cluster. Almost immediately, we were faced with the dilemma of what to do with the ZooKeeper cluster. Formally, we did not need it since we were not going to add any replicas to it. However, it is better to copy the existing configuration, right? In this case, the developers don’t have to think about where to create tables, and we would be able to quickly change the cluster topology, e.g., by adding shards and/or replicas.
But what about ZooKeeper? We did not have the resources to create the additional ZK cluster on the existing infrastructure. At the same time, we did not want to set up a new ZK cluster on the servers used for a new ClickHouse — mixing VM roles is a famous anti-pattern, isn’t it? That is why we decided to use the existing ZK cluster for a new CH cluster. This solution does not seem to cause any troubles (and is entirely appropriate in terms of performance).
And so we did that: we started the new CH instance (that uses the current ZK cluster) and provided access to developers.
Here is our resulting architecture:
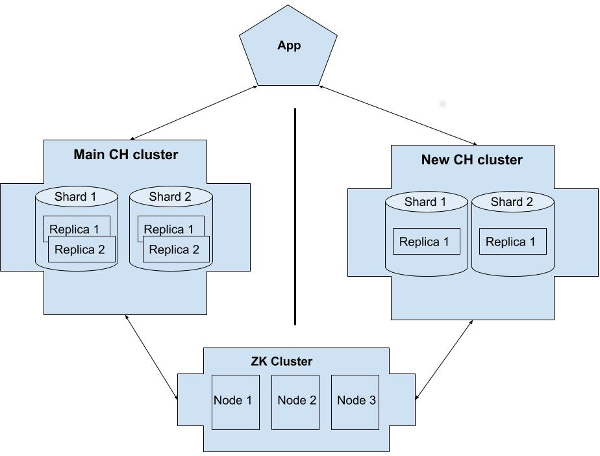
There were no signs of upcoming trouble…
The incident
A few days have passed. It was a beautiful sunny weekend day and my shift. Late in the afternoon, I got an issue related to ClickHouse clusters: one of the tables in the primary CH cluster that stores the processed data had stopped performing writes.
Concerned, I started to analyze the monitoring data of the Linux systems used in CH clusters. At first sight, there were no signs of trouble: no increased replica load, no apparent issues with server subsystems.
However, while examining logs and system CH tables, I noticed some disturbing errors:
2020.10.24 18:50:28.105250 [ 75 ] {} <Error> enriched_distributed.Distributed.DirectoryMonitor: Code: 252, e.displayText() = DB::Exception: Received from 192.168.1.4:9000. DB::Exception: Too many parts (300). Merges are processing significantly slower than inserts.. Stack trace:I took a look into replication_queue and discovered hundreds of lines with an error about the inability to replicate data to the server of the new cluster. At the same time, the error log of the main cluster contained entries like this:
/var/log/clickhouse-server/clickhouse-server.err.log.0.gz:2020.10.24 16:18:33.233639 [ 16 ] {} <Error> DB.TABLENAME: DB::StorageReplicatedMergeTree::queueTask()::<lambda(DB::StorageReplicatedMergeTree::LogEntryPtr&)>: Poco::Exception. Code: 1000, e.code() = 0, e.displayText() = DNS error: Temporary DNS error while resolving: clickhouse2-0 (version 19.15.2.2 (official build)… and this:
2020.10.24 18:38:51.192075 [ 53 ] {} <Error> search_analyzer_distributed.Distributed.DirectoryMonitor: Code: 210, e.displayText() = DB::NetException:
Connection refused (192.168.1.3:9000), Stack trace:
2020.10.24 18:38:57.871637 [ 58 ] {} <Error> raw_distributed.Distributed.DirectoryMonitor: Code: 210, e.displayText() = DB::NetException: Connection refused (192.168.1.3:9000), Stack trace:At that moment, an idea came to my mind about what had happened. To confirm it, I ran SHOW CREATE TABLE for the table with issues and studied output. Yeah, you guessed it right — ZKPATH turned out to be the same in both clusters!
ENGINE = ReplicatedMergeTree('/clickhouse/tables/DBNAME/{shard}/TABLENAME', '{replica}')Let me summarize:
- we use the same ZK cluster;
- shard numbers are identical in both CH clusters;
- names of the replicated tables are also identical;
ZKPATHis the same for both clusters.
So ClickHouse thinks that all these replicas are related to the same table. And, consequently, they must replicate each other.
It turns out, we forgot to tell the developers that the same ZK cluster is used with both CH clusters. Thus, they didn’t take into account this circumstance while specifying ZKPATH for tables in the new cluster.
The factor of delayed failure contributed to the overall confusion during the initial stages of troubleshooting. We handed over the new cluster to the developers in the middle of the week, and it took them a few more days to start creating tables and writing data into them. That is why the problem manifested itself later than could have been expected.
The solution
Fortunately, the servers of both clusters were isolated from each other on the network layer. Thanks to this, the data did not turn into a mess.
Realizing what had happened, I drew up the following action plan:
- cautiously separate these clusters/replicas from each other;
- keep the data that were not replicated (stuck in the
replication_queue); - preserve the operability of the main cluster.
The fact that I could lose the data in the new cluster (as well as the new cluster itself) without any consequences simplified my task significantly.
The first obvious step is to DROP the problem table on each replica of the new cluster. According to the documentation, it should lead to the following outcome:
- the table containing the data will be deleted on the replica where
DROPis performed (I double-checked this to make sure that the table on the main cluster will stay intact); - the metadata related to this replica will be deleted from the ZK cluster (which is what I needed).
So, we had two shards, each containing one replica called clickhouse2-0 and clickhouse2-1 (hereinafter referred to as server 2-0 and server 2-1, respectively).
The DROP TABLE command worked out as expected on server 2-0. Unfortunately, that was not the case with server 2-1: part of the key tree containing data about this replica was stuck in the ZK service.
Then I tried to execute:
rmr /clickhouse/tables/DBNAME/2/TABLENAME/replicas/clickhouse2-1… and got the node not empty error. It is quite strange since the above command should delete znode recursively.
The ClickHouse documentation contains information about system commands for DROP‘ping ZK keys related to specific replicas. I could not use them on the primary cluster because of the older ClickHouse version (19), while these commands became available in version 20. Happily, the new cluster had the newer CH version installed, and I took advantage of this fact:
SYSTEM DROP REPLICA 'replica_name' FROM ZKPATH '/path/to/table/in/zk';
… and it worked!
Now I had the cleaned-up ZK cluster (free of any redundant replicas), but the primary CH cluster still did not work for some reason. Why? The thing is that replication_queue it was still clogged with junk records. So the final step is to deal with the replication queue. After that, everything should be fine (well… at least, in theory).
As you know, the replication queue is stored in the keys of the ZK cluster, namely:
/clickhouse/tables/DBNAME/1/TABLENAME/replicas/clickhouse-0/queue/I used the CH’s replication_queue table to find out what keys can and should be deleted. The nodename field is available when performing SELECT. This field is the same as the key name specified in the above path.
The rest is history: collect all the keys related to the problem replicas:
clickhouse-client -h 127.0.0.1 --pass PASS -q "select node_name from system.replication_queue where source_replica='clickhouse2-1'" > bad_queueidAnd then remove them in the ZK cluster:
for id in $(cat bad_queueid); do
/usr/share/zookeeper/bin/zkCli.sh rmr /clickhouse/tables/DBNAME/2/TABLENAME/replicas/clickhouse-1/queue/$id;
sleep 2;
doneHere, you have to be careful and delete keys using the path of the shard for which SELECT was performed.
Thus, I collected all the “bad” tasks in the replication queue of each replica of each shard and deleted them in the ZK cluster. After that, both CH clusters started running smoothly (including writing data to the main cluster).
As a result of all these manipulations, I was able to keep all the data; all valid replication tasks were performed as expected, and the cluster operation returned to normal.
Takeaways
What lessons can be learned from this situation?
- You have to discuss with colleagues the solution you are going to implement tentatively and in the process. Make sure that they clearly understand the key points and possible nuances.
- As they say, measure twice and cut once. When designing a solution, consider various scenarios when (and why) something might go wrong. You should examine all the possible alternatives, including the most improbable. Here, it pays to be meticulous and attentive to details. At the same time, remember that you simply cannot take into account all the possibilities.
- While preparing the infrastructure for developers, provide its full and most detailed description to avoid incidents like the one described above. It is even more crucial when it comes to closely tied areas (as in our case) when some Dev-related settings (part of the table schema) directly affected the infrastructure operated within the scope of Ops. You have to identify such areas in advance and pay special attention to them.
- Try to avoid any hardcoding or name duplicating, especially when it comes to identical logical elements of the infrastructure, such as ZooKeeper paths, database/table names in the neighboring DB clusters, addresses of external services in the configuration files. All these parameters must be configurable. Of course, do that to the extent feasible.
In addition to the organizational aspects, I would like to note the outstanding resilience of ClickHouse to various types of failures and (which is even more important) the remarkable reliability of the data storage mechanism of this database. In the case of CH, if you follow the basic recommendations and principles of the cluster configuration, then you will not lose your data no matter how hard you try (except for the malicious intent, of course).

Comments