

Leveraging Kubernetes in your CI/CD processes, you can’t just stop your application: firstly, it should stop receiving new requests and — which is even more significant — to complete the existing ones.
By implementing this strategy, you can avoid any downtime during the deployment process. However, even using very popular technologies (such as NGINX and PHP-FPM), you still can encounter challenges that will lead to a surge of errors with each deployment. To illustrate it, I’ll start with a brief theory.
Theory. Pod’s lifecycle
A perfect, detailed description of a pod’s life has been already given here. In our case, we are mostly interested in the moment when a pod enters the Terminating state. At that stage, it stops receiving new requests since the pod is deleted from endpoints list of the service. In other words, to avoid downtime during the deployment process, we have to address the issue of graceful shutdown of an application.
By default, the grace period equals to 30 seconds. When the grace period expires, all the processes in the pod are killed with SIGKILL. Thus, an application must complete all requests until the grace period is over.
Side note: On the other hand, you can consider any request that is still running after 5–10 seconds to be the troubled one, hence the graceful shutdown won’t change anything.
Take a look at the chart below in order to better understand what is happening when a pod is being deleted:
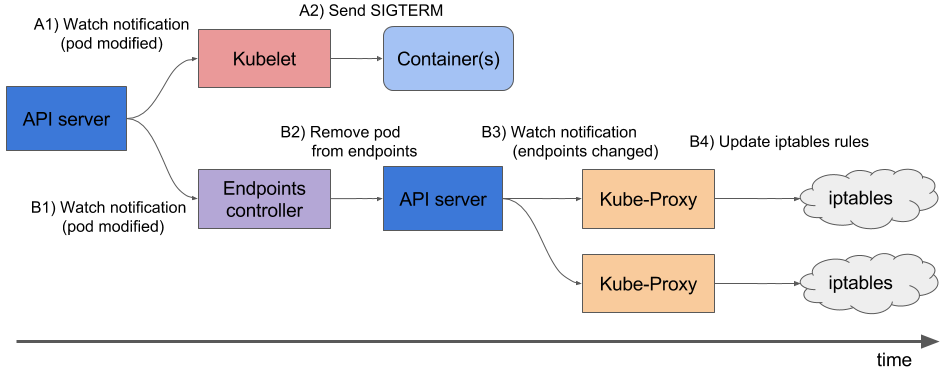
Please note that removing the pod from endpoints and sending the SIGTERM signal occur concurrently rather than sequentially. Ingress controllers get an updated list of endpoints with some delay, and new traffic continues to be sent to the pod. As a result, clients are getting 5XX errors during the termination of the pod (here is a more detailed description of this case). There are several ways to deal with this problem:
- Use the
Connection: closeheader in the response message (for HTTP applications). - But what if you cannot modify the code for some reason? Well, there is a solution to this problem (it will be outlined below), allowing an application to service requests until the end of the graceful period.
Theory. How NGINX and PHP-FPM shut down their processes
NGINX
Let’s start with NGINX since it is more intuitive. As you know, it has one master process and several workers (child processes). The workers handle network connections and client requests. Using nginx -s , you can shut down processes immediately (the so-called fast shutdown) or gracefully. Obviously, we are interested in the latter option.
Well, everything is easy now. You have to add the command to your preStop hook that will send a signal for a graceful shutdown. This command should be nested under the container specification in the Deployment configuration file:
lifecycle:
preStop:
exec:
command:
- /usr/sbin/nginx
- -s
- quitAs a result, the following messages will appear in the NGINX container logs:
2018/01/25 13:58:31 [notice] 1#1: signal 3 (SIGQUIT) received, shutting down
2018/01/25 13:58:31 [notice] 11#11: gracefully shutting downThat is what we need! NGINX waits until requests are complete and then kills the process. However, there is quite a common problem: sometimes, even with nginx -s quit, the process terminates incorrectly. This issue will be described below.
For now, we are done with NGINX: logs show that everything is working correctly.
What about PHP-FPM? How does it handle graceful shutdowns? Let’s find out!
PHP-FPM
In the case of PHP-FPM, the information is less readily available. The official manual states that PHP-FPM supports the following POSIX signals:
SIGINT,SIGTERM— fast shutdown;SIGQUIT— graceful shutdown (that is what we need!).
The remaining signals are beyond the scope of this article. The following preStop hook allows you to terminate the process correctly:
lifecycle:
preStop:
exec:
command:
- /bin/kill
- -SIGQUIT
- "1"At first glance, this is all you need to perform a graceful shutdown in both containers. However, the task is certainly more complicated than it seems. Below we examine two interesting cases when a graceful shutdown did not work out as planned, leading to short-term inaccessibility of the application during the deployment.
Practice. Potential problems with graceful shutdown
NGINX
First of all, in addition to the nginx -s quit command, there is another nuance worth paying attention to. On several occasions, we have run into a strange problem when NGINX has sent SIGTERM instead of SIGQUIT. Because of that, the requests did not finish gracefully (more variations on the same issue). Unfortunately, we haven’t been able to find out what the reasons are behind this strange behavior. The version conflict was our prime suspect, but it was not confirmed. In the logs of the NGINX container, we have observed messages like “open socket #10 left in connection 5”, and then the pod has been killed.
The problem becomes evident if you study, say, responses at the corresponding Ingress:

In this case, the 503 errors originate at the Ingress itself: the controller cannot connect to the NGINX container (it is unavailable). Logs of the NGINX container have the following lines:
[alert] 13939#0: *154 open socket #3 left in connection 16
[alert] 13939#0: *168 open socket #6 left in connection 13However, if you replace SIGTERM with SIGQUIT, the container begins to shut down gracefully, which is confirmed by the absence of 503 errors.
So, here is our advice for those who have encountered a similar problem: first of all, figure out what kind of terminating signal is used in your container and analyze the contents of your preStop hook. You may find the answer/solution sooner than you thought.
PHP-FPM and more
The problem with PHP-FPM is quite trivial: this process manager does not wait for the completion of child processes and kills them, causing 502 errors during the deployment process and other tasks. The bugs.php.net tracker has many messages reporting similar issues (e.g., here and here). Logs do not help either: most likely, there will be no info at all regarding the issue. PHP-FPM simply states the termination of its process without any error messages or additional notifications/alerts.
It is worth clarifying that the problem may depend more or less on the application, and it may not manifest itself, for example, in monitoring. Here is a simple workaround for those who have similar issues: insert the sleep(30) command into your preStop hook. Thus, the container will be able to complete all the active requests (there are no new ones since the pod is in the Terminating state already). In this case, after 30 seconds, the pod will exit with a SIGTERM.
The lifecycle snippet in the container configuration is shown below:
lifecycle:
preStop:
exec:
command:
- /bin/sleep
- "30"Tricky part is that the 30-second sleep will considerably increase the duration of the deployment process since each pod will be terminating for 30 seconds at least. It is bad, so what can you do about it?
Let’s turn to the entity controlling the execution of the application. In our case, PHP-FPM does not control its child processes by default: the master process terminates as soon as it gets the signal. You can change this behavior with the process_control_timeout directive (it specifies a grace period for workers). By setting it to 20 seconds, you will cover most of the requests running in your container, and the master process will be terminated after their completion.
Now, let’s get back to our case. If you recall, Kubernetes is not monolithic, and interaction between its parts takes some time. It is especially true for Ingresses and other related components because such a delay during the deployment will result in 5XX errors. For example, an error may occur when sending a request to the upstream (even if the time lag between components is rather short — less than a second).
The above method together with the process_control_timeout parameter give us the following expression for the lifecycle:
lifecycle:
preStop:
exec:
command: ["/bin/bash","-c","/bin/sleep 1; kill -QUIT 1"]Thus, we cover the delay using the sleep command while keeping the duration of the deployment process almost at the same level — after all, one second is much less than thirty. In a sense, the process_control_timeout parameter does most of the work, while the lifecycle serves as a safety net in case of a lag.
The above behavior, as well as the workaround, are not limited to PHP-FPM. A similar situation may arise with other languages/app servers, too. You can use the method described above to ensure a graceful shutdown if you are running an application that cannot be modified to handle the termination signals correctly. Granted, this is not the prettiest method, but it works anyway.
Load testing: checking for the presence of errors
Load testing is one of the ways to check if the container behaves as it should. This procedure brings the container closer to real-life conditions when multiple users visit the site simultaneously. Yandex.Tank was used for testing all of the above recommendations and methods since it meets our needs perfectly. Below, you may find tips and tricks for load testing based on an illustrative, real-life example (thanks to the visualization capabilities of Grafana as well as the Yandex.Tank itself).
The most important thing here is to test changes in a phased manner. You start with a new fix, implement it, run the test, and see if the results differ compared to the previous run. Otherwise, it will be hard to identify ineffective solutions, and they can even be harmful (for example, they might increase the deployment time).
But here comes another nuance. We recommend you to analyze your container logs relevant to its termination. Are there any hints of a graceful shutdown? Are there any errors when accessing other resources (e.g., to a PHP-FPM sidecar-container)? Are there any errors of the application itself (as in the NGINX case described above)? We hope this article will help you to better understand what happens to the container when it is terminating.
In our first test run, we made no changes to the lifecycle field and provided no additional directives (like PHP-FPM’s process_control_timeout) to the application server. The purpose of that test was to get a sense of the approximate number of errors (and if we have any at all). As a side note, the average duration of deploying each pod up to the state of complete readiness amounted to about five to ten seconds. Here are the results:
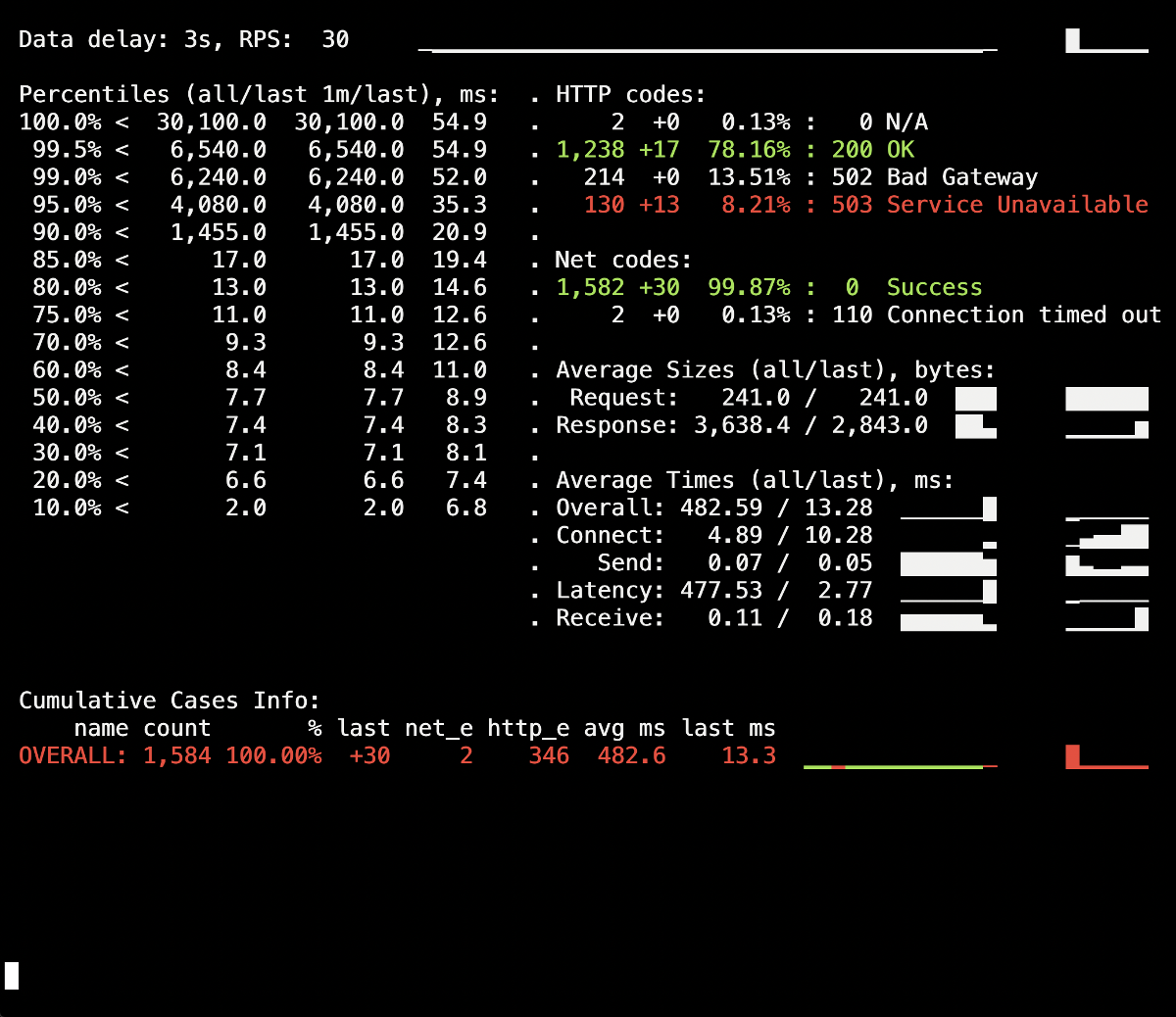
You may see a surge of 502 errors, which occurred during the deployment and lasted up to five seconds on average. We think this is due to failing requests to the old pod during its termination. After that, there was a surge of 503 errors caused by a stopping NGINX container that has lost its connections (the Ingress could not connect to it).
Let’s see if setting the process_control_timeout parameter can help us to fix these errors and shut down child processes gracefully. Here are the results of another test run with a set process_control_timeout:
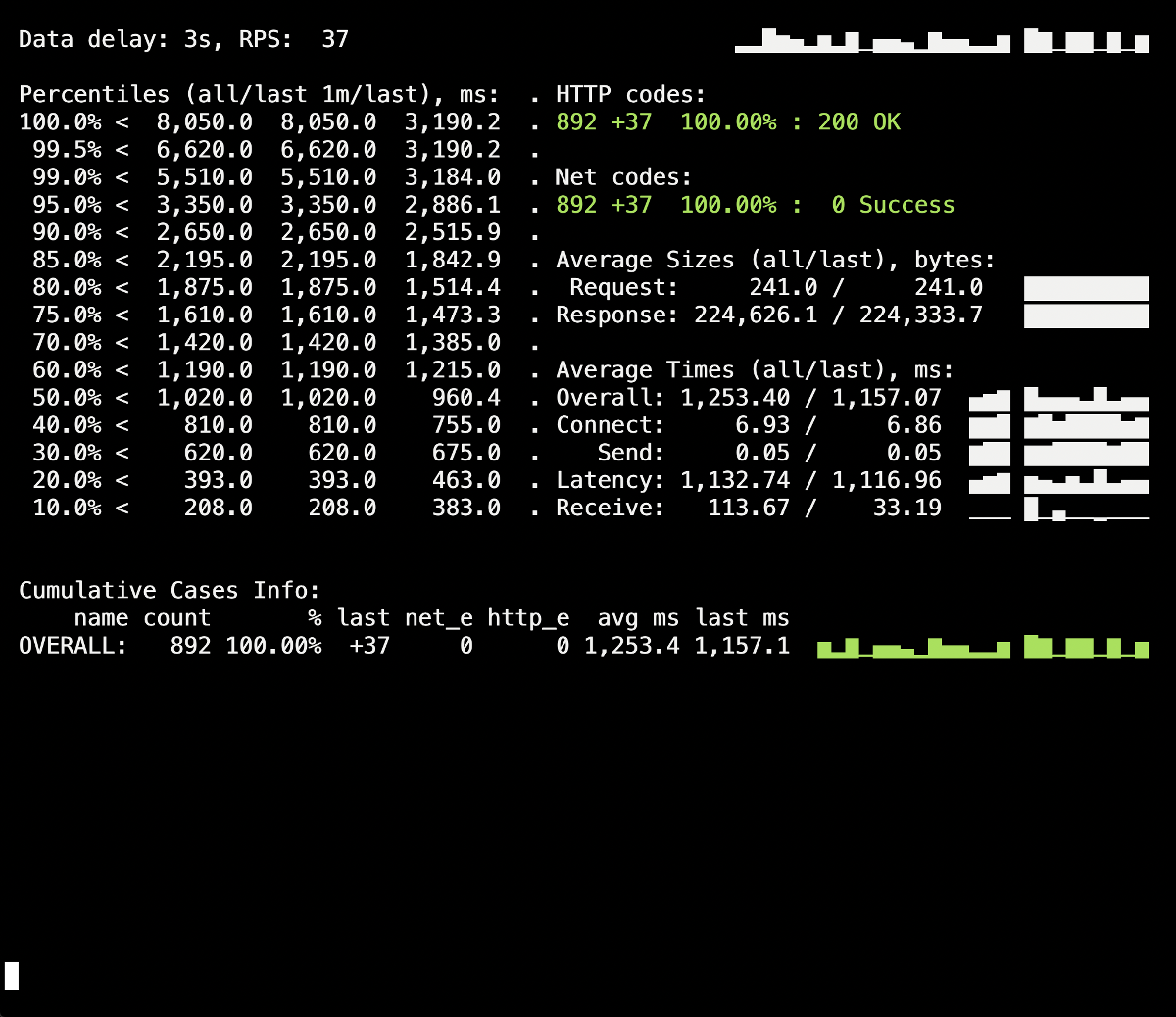
There are no more 5XX errors during the deployment! The process goes as planned, and the graceful shutdown works fine.
And what about Ingress containers? As you recall, the small percentage of errors is caused by the time lag. To avoid them, you can introduce the delay (via the sleep command) as part of the preStop hook and redeploy the cluster. However, in our particular case, there were no visible changes (no errors occurred).
Conclusion
The graceful shutdown of the process involves the following steps:
- An application must wait a few seconds, then stop accepting new connections;
- An application must wait until all requests are complete and close all idle keepalive connections;
- It must terminate its own process.
Alas, not all applications can do this. To solve this problem in the Kubernetes cluster, you must:
- Add the preStop hook with a specific delay;
- Analyze your backend configuration and pick out relevant parameters.
The NGINX example illustrates the fact that there is always a possibility of an incorrect shutdown even if an application has all the necessary parameters set for a graceful one. That is why you should always check the logs for the presence of 5XX errors when deploying an application. Also, such a practice allows you to look at the problem more broadly and not to dwell on a specific pod or a container but examine the entire infrastructure.
For testing, you can use the stack consisting of the Yandex.Tank and monitoring system (in our case, we use the combination of Prometheus and Grafana). The issues with a graceful shutdown manifest itself during high-load periods, which the benchmark successfully generates, while monitoring tools help with the detailed analysis of the situation during and after testing.
It is worth mentioning that the problems described here relate only to the NGINX Ingress. For other cases/software stacks, there might be other solutions, and we will discuss them in future articles in this series.

Comments