

We regularly deal with the Apache Cassandra and the need to operate it as a part of a Kubernetes-based infrastructure (for example, for Jaeger installations). In this article, we will share our vision of the necessary steps, criteria, and existing solutions for migrating Cassandra to K8s.
“The one who can control a woman can cope with the country as well”
What is Cassandra? Cassandra is a distributed NoSQL DBMS designed to handle large amounts of data. It provides high availability with no single point of failure. The project hardly needs a detailed introduction, so I will only remind you of those main features of Cassandra that are important in the context of this article.
- Cassandra is written in Java.
- The topology of Cassandra includes several layers:
- Node — the single deployed instance of Cassandra;
- Rack — the collection of Cassandra’s instances grouped by some attribute and located in the same data center;
- Datacenter — the combination of all Racks located in the same data center;
- Cluster — the collection of all Datacenters.
- Cassandra uses an IP address to identify a node.
- Cassandra stores part of the data in RAM to speed up reading and writing.
And now, let’s get to the actual migration to Kubernetes.
Migration check-list
What we’re not going to discuss here is the reason for migrating Cassandra to Kubernetes. For us as a company maintaining a lot of K8s clusters, it’s all about managing it in a more convenient way.
So, we’d rather focus on what we need to make this transition possible and what tools can help us with this.
1. Data storage
As we mentioned above, Cassandra stores some of its data in RAM, in the form of MemTable. There is another part of the data that is saved to disk as SSTable. Cassandra also has a unique instance called Commit Log that keeps records of all transactions and is stored on disk.
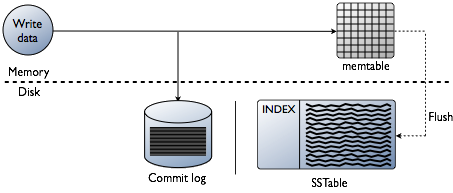
In Kubernetes, there is a PersistentVolume for storing data. You can use this mechanism effortlessly since it is already well developed.
We wish to emphasize that Cassandra itself has built-in mechanisms for data replication. Therefore, there is no need to use distributed data storage systems like Ceph or GlusterFS in the case of a Cassandra cluster comprising a large number of nodes. In this situation, the most appropriate solution is to store data on the node’s disk via local persistent volumes or by mounting hostPath.
On the other hand, what if you want to create a separate environment for developers for each feature branch? In this case, the correct approach is to create a single Cassandra node and store data in the distributed storage (i.e., Ceph and GlusterFS become an option). This way, you can ensure the safety of the test data even if one of the nodes of the Kubernetes cluster fails.
2. Monitoring
We consider Prometheus the best tool available for event monitoring in Kubernetes. Does Cassandra support exporters for Prometheus metrics? And (that is even more important) does it support matching dashboards for Grafana?
There are only two exporters: jmx_exporter and cassandra_exporter.
We prefer the first one, because:
- JMX Exporter is growing and developing steadily, whereas Cassandra Exporter was unable to gain the support of the community (Cassandra Exporter still does not support most of Cassandra’s versions).
- You can run JMX Exporter as a javaagent by adding the following flag:
-javaagent:<plugin-dir-name>/cassandra-exporter.jar=--listen=:9180. - JMX Exporter has a neat dashboard, incompatible with Cassandra Exporter.
3. Choosing Kubernetes primitives
Let’s try to convert the structure of the Cassandra cluster (outlined above) to Kubernetes resources:
- Cassandra Node → Pod
- Cassandra Rack → StatefulSet
- Cassandra Datacenter → pool of StatefulSets
- Cassandra Cluster → ???
It looks like we need some additional Kubernetes resource that corresponds to the Cassandra Cluster. Thanks to the Kubernetes mechanism for defining custom resources (CRDs), we can easily create the missing resource.
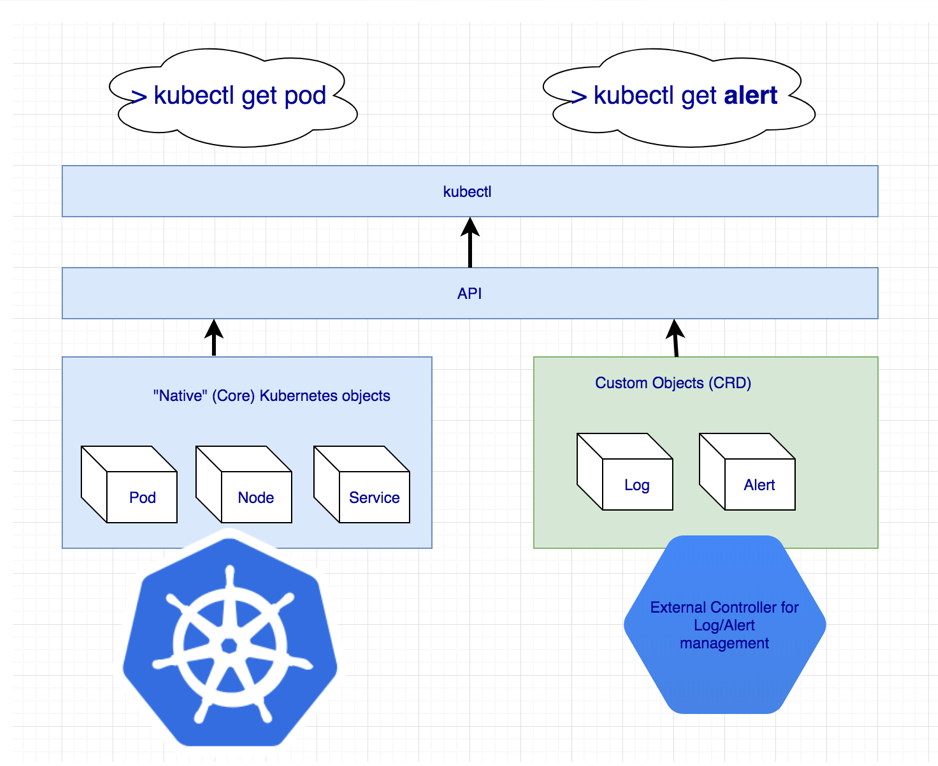
But the Custom Resource isn’t enough — you need a corresponding controller. You even may have to use a Kubernetes operator.
4. Identifying pods
Previously we decided that each Cassandra node corresponds to one pod in Kubernetes. As you know, Cassandra identifies pods by their IP addresses. However, the IP address of the pod will be different each time. It looks like that after each pod deletion, you will have to add a new node to the Cassandra cluster.
Still, there is a way out… more like several of them:
1. We can track pods by host identifiers (UUIDs that explicitly identify Cassandra instances) or by IP addresses and save all that info into some structure/table. However, this approach has two main disadvantages:
- Risk of racing conditions in the case of simultaneous failure of two or more pods. After the redeployment, Cassandra nodes will attempt to get an IP address from the table at the same time, competing for the same resource.
- It will not be possible to identify the Cassandra node that has lost its data.
2. The second solution looks like a small, innocent hack: we can create a Service with the ClusterIP for each Cassandra node. Such an approach has the following disadvantages:
- If the Cassandra cluster has a considerable amount of nodes, we will have to create a large number of Services.
- The ClusterIP access mode is based on iptables. This could be a problem if the Cassandra cluster has a large number of nodes (1000 or even 100). The IPVS-based in-cluster load balancing can solve it, though.
3. The third solution is to use a node network for Cassandra nodes in place of a dedicated pod network by setting hostNetwork: true. This approach has certain limitations:
- Replacing nodes. The new node has to have the same IP address as the previous one (this behavior is almost impossible to implement in the clouds such as AWS, GCP);
- By using the network of cluster nodes, we start to compete for network resources. Therefore, it will be rather difficult to deploy more than one pod containing Cassandra to the same cluster node.
5. Backups
What if we want to backup all data from some Cassandra node according to the schedule? Kubernetes provides an excellent tool for such tasks, CronJob. However, Cassandra’s specific nature prevents us from doing this.
Let me remind you that Cassandra stores parts of the data in memory. To do a full backup, you have to flush in-memory data (Memtables) to the disk (SSTables). In Cassandra’s terminology, that process is called a “node drain”: it makes a Cassandra node stop receiving connections and become unreachable — an unwanted behaviour in most cases.
Then the node backs up the data (by saving a snapshot) and saves the scheme (keyspace). However, there is one problem: the backup itself isn’t sufficient. We also have to preserve data identifiers (in the form of dedicated tokens) for which the Cassandra node is responsible.
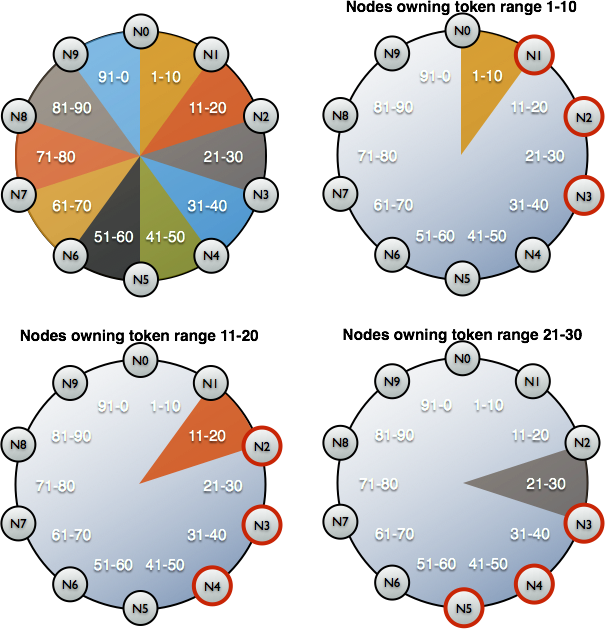
Here you may find an example of a Google-made script for backing up files from Cassandra cluster in Kubernetes. This script is good except for it doesn’t flush data to the node before making a snapshot. That is, the backup is performed not for a current but a little earlier state. However, this approach preserves the node’s availability, which seems quite logical and beneficial.
An example of a Bash script for backing up files on a single Cassandra node:
set -eu
if [[ -z "$1" ]]; then
info "Please provide a keyspace"
exit 1
fi
KEYSPACE="$1"
result=$(nodetool snapshot "${KEYSPACE}")
if [[ $? -ne 0 ]]; then
echo "Error while making snapshot"
exit 1
fi
timestamp=$(echo "$result" | awk '/Snapshot directory: / { print $3 }')
mkdir -p /tmp/backup
for path in $(find "/var/lib/cassandra/data/${KEYSPACE}" -name $timestamp); do
table=$(echo "${path}" | awk -F "[/-]" '{print $7}')
mkdir /tmp/backup/$table
mv $path /tmp/backup/$table
done
tar -zcf /tmp/backup.tar.gz -C /tmp/backup .
nodetool clearsnapshot "${KEYSPACE}"Ready-made Cassandra solutions for Kubernetes
What tools help to deploy Cassandra to the Kubernetes cluster? Which of those are the most suitable for the given requirements?
1. StatefulSet or Helm-chart-based solutions
Using standard StatefulSets functionality for deploying Cassandra cluster is a great idea. By using Helm charts and Go templates, you can provide the user with a flexible interface for deploying Cassandra.
Normally, this method works just fine — until something unexpected happens (e.g., failure of a node). The standard Kubernetes tools cannot handle all the above nuances. Also, this approach isn’t scalable enough for more complicated uses: replacing nodes, backing up data, restoring, monitoring, etc.
Examples:
Both charts are equally good but suffer from the issues described above.
2. Solutions based on Kubernetes Operator
These tools are preferable since they provide extensive cluster management capabilities. Here is the general pattern for designing an operator for Cassandra (as well as for any other DBMS): Sidecar Controller CRD.
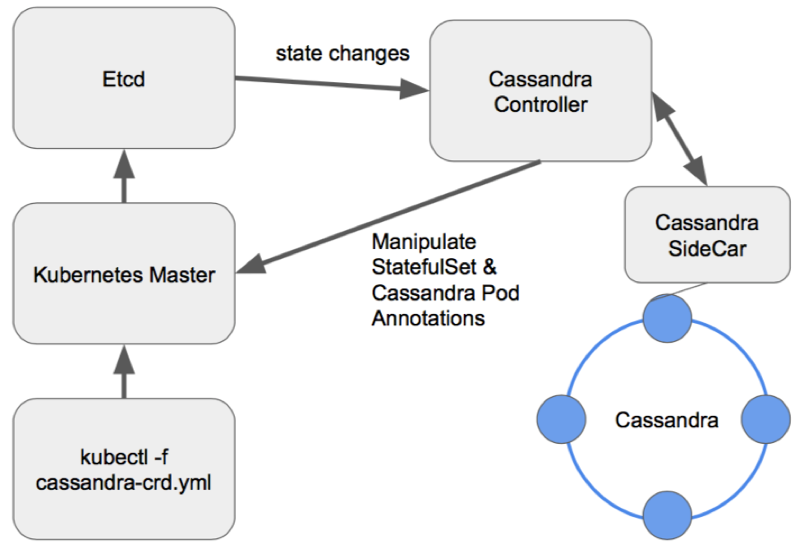
Let’s review the available operators:
2.1. Cassandra-operator by instaclustr
- GitHub
- Maturity: Alpha
- License: Apache 2.0
- Written in: Java
A surprisingly promising and rapidly developing tool made by the company that offers Cassandra managed deployments. It uses a sidecar container that gets commands via HTTP. Cassandra-operator is written in Java and sometimes lacks advanced functionality of the client-go library. The operator doesn’t support different Racks for the same Datacenter.
However, Cassandra-operator has several pros such as support for monitoring, high-level cluster management via CRD, or even detailed instructions on making a backup.
2.2. Navigator by Jetstack
- GitHub
- Maturity: Alpha
- License: Apache 2.0
- Written in: Go
Navigator is a Kubernetes extension for implementing DB-as-a-Service. Currently, it supports Elasticsearch and Cassandra databases. The operator possesses several intriguing concepts, such as access control to the database via RBAC (for this, a separate navigator-apiserver is started). Overall, this project is worth a closer look. Unfortunately, the latest commit was over 18 months ago, and that fact severely reduces its potential.
2.3. Cassandra-operator by vgkowski
- GitHub
- Maturity: Alpha
- License: Apache 2.0
- Written in: Go
We haven’t seriously considered this operator because the latest commit was over a year ago. The operator is abandoned: the latest supported version of Kubernetes is 1.9.
2.4. Cassandra-operator by Rook
- GitHub
- Maturity: Alpha
- License: Apache 2.0
- Written in: Go
This operator isn’t developing as rapidly as we would like. It has a well-thought-out CRD structure for managing cluster and solves the problem of node identification by implementing a Service with a ClusterIP (the hack we’ve mentioned above), but that’s all for now. It doesn’t support monitoring and backing up out-of-the-box (though we are working on the monitoring part currently). The interesting point is that Cassandra-operator also works with ScyllaDB.
NB: We have used this operator (with a little tweaking) in one of our projects. There were no problems during the entire period of operation (~4 months).
2.5. CassKop by Orange
- GitHub
- Maturity: Alpha
- License: Apache 2.0
- Written in: Go
CassKop is the youngest operator on our list. Its main difference from other operators is the support for CassKop plugin, which is written in Python and used to communicate between Cassandra nodes. The very first commit was on May 23, 2019. However, CassKop has already implemented a large number of features from our wish list (you can learn more about them in the project’s repository). This operator is based on the popular operator-sdk framework and supports monitoring right out-of-the-box.
2.6. Cass-operator by DataStax (ADDED in June’20)
- GitHub
- Maturity: Beta
- License: Apache 2.0
- Written in: Go
This operator, introduced to the Open Source community quite recently (in May 2020), was developed by DataStax. Its main objective is automating the process of deploying and managing Apache Cassandra. Cass Operator naturally integrates many popular DataStax tools, such as metric-collector for aggregating Cassandra metrics (bundled with Grafana dashboards) and cass-config-builder for generating Cassandra configs. The operator interacts with Cassandra using the management-api sidecar. Thus, you will have to use specialized Docker images to deploy Cassandra. The emergence of the operator is an excellent opportunity to familiarize yourself with DataStax recipes for “cooking” Cassandra.
Takeaways
A large number of approaches and a variety of migration options suggest the existing demand for moving Cassandra to Kubernetes.
Currently, you can try any of the above methods at your own risk: none of the developers guarantees the smooth running of their brainchildren in the production environment. Yet many projects already look promising and are ripe for testing.
Maybe that Cassandra isn’t so cursed even in Kubernetes after all…

Comments