

MongoDB is one of the most popular NoSQL/document-oriented databases in the world of web development. For that reason, many of our clients use it in their applications (including production-grade apps). Many of those applications are running on Kubernetes. In this article, we would like to share our experience in running MongoDB on K8s. What options are out there? What are the intricacies of them? What approach do we take to this task?
It’s no secret: even though Kubernetes provides a large number of advantages in scaling and administering applications, you can get into a lot of trouble if you do it without proper planning and care. The same is true for MongoDB on Kubernetes.
Main challenges
There are some things to take into account when you are deploying Mongo into the cluster:
- Storage goes first. Remote storage is best if you have a need for maximum flexibility when running Mongo on Kubernetes. You can easily switch remote disks between nodes if you have a need to migrate Mongo to upgrade cluster nodes or delete them. However, remote disks usually have a lower IOPS (compared to local disks). You have to take that into account if your database is running under high load and requires good latency readings.
- Setting correct resource requests and limits for Pods with Mongo replicas running (as well as on other Pods of the same node). Since Kubernetes is “friendlier” to stateless applications, you may encounter undesirable behavior if requests and limits aren’t configured correctly. In particular, Kubernetes may respond to a suddenly increased load by killing Mongo pods and moving them to nodes with less of a load on them. Even more frustratingly, starting a Mongo Pod on another node may take a long time. The situation is further complicated if the replica that was killed was the primary one. In that case, a new primary replica would then be elected, all write operations would stop, and the application would have to wait until the election process is over.
- In addition to the point we just mentioned: Kubernetes can quickly scale nodes and move Mongo over to nodes with more resources on them, even if they currently have a high (peak) load on them. For that reason, we recommend using podDisruptionBudget. This Kubernetes primitive sets a maximum for the number of Mongo Pods that can be down at the same time and ensures that the number of replicas running is never below the required number.
By addressing these challenges, you will gain a database that can scale quickly, whether vertically or horizontally, and run in the same environment along with other applications. Furthermore, it will be convenient for you to manage using common Kubernetes mechanisms. As for reliability, it all depends on how well the database deployment in the cluster was planned (taking into account major negative scenarios).
Fortunately, today, most providers have a huge selection of storage options to choose from, from network disks to local disks with impressive IOPS readings. Only network disks are suitable for dynamic scaling of the MongoDB cluster (once again, you have to take into account that they are slower than local disks). Here is a Google Cloud comparison that confirms that: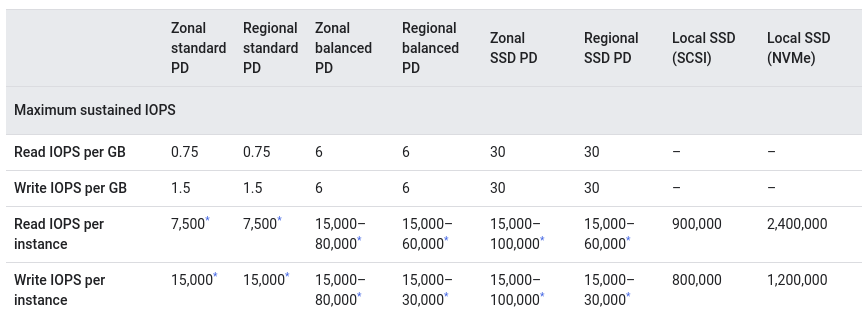
There are also additional factors they may depend on: In AWS, the situation is slightly better, but it is still a far cry from the performance of local disks:
In AWS, the situation is slightly better, but it is still a far cry from the performance of local disks:
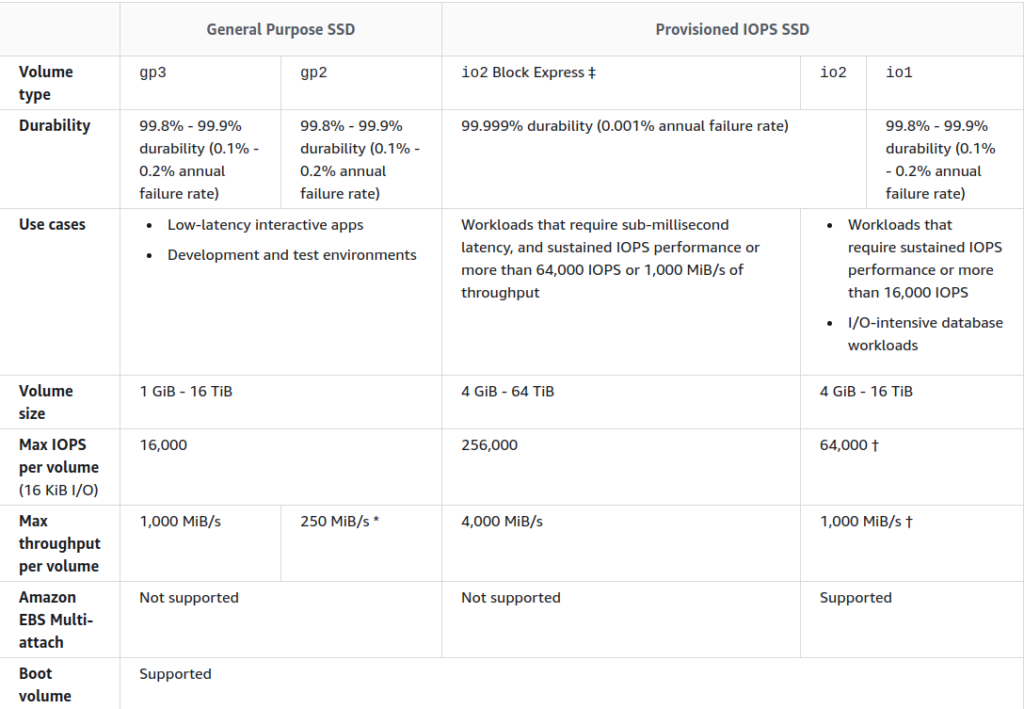
Based on our experience, in the vast majority of cases, regular network disks are a perfect fit.
Firing up the MongoDB cluster on Kubernetes
As you might guess, in any situation, you can devise your own solution by making a few manifests with a StatefulSet and an init-script (and Mongo is no exception here). However, in this article, we will review some existing approaches that “were invented for us a long time ago.”
1. Helm chart by Bitnami
The Helm chart by Bitnami is the first option on our list. It is popular, well-known, and actively maintained.
The chart allows you to run MongoDB in several different ways:
- standalone;
- replica set (from here on out, we will use the MongoDB terminology by default; all ReplicaSets in the Kubernetes sense will be explicitly stated);
- replica set + arbiter.
This Helm chart makes use of its own (i.e., unofficial) image.
The chart is well parameterized and documented. The flip side of the coin: the chart is filled with a whole range of functions and you have to figure out what you really need. It is very much like a constructor that allows you to build the configuration you need.
Here are some basic steps you need to complete to run MongoDB:
- Define the architecture (Values.yaml#L125-L127). By default, it runs as a standalone instance, but we are more interested in a replica set:
...
architecture: replicaset
...- Specify the storage type and size (Values.yaml#L765-L818):
...
persistence:
enabled: true
storageClass: "gp2"
accessModes:
- ReadWriteOnce
size: 120Gi
...Now you can get the MongoDB cluster up and running using helm install (note that instructions on how to connect to the database from within the cluster are given in the command’s output):
NAME: mongobitnami
LAST DEPLOYED: Fri Feb 26 09:00:04 2021
NAMESPACE: mongodb
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
** Please be patient while the chart is being deployed **
MongoDB(R) can be accessed on the following DNS name(s) and ports from within your cluster:
mongobitnami-mongodb-0.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017
mongobitnami-mongodb-1.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017
mongobitnami-mongodb-2.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017
To get the root password run:
export MONGODB_ROOT_PASSWORD=$(kubectl get secret --namespace mongodb mongobitnami-mongodb -o jsonpath="{.data.mongodb-root-password}" | base64 --decode)
To connect to your database, create a MongoDB(R) client container:
kubectl run --namespace mongodb mongobitnami-mongodb-client --rm --tty -i --restart='Never' --env="MONGODB_ROOT_PASSWORD=$MONGODB_ROOT_PASSWORD" --image docker.io/bitnami/mongodb:4.4.4-debian-10-r0 --command -- bash
Then, run the following command:
mongo admin --host "mongobitnami-mongodb-0.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017,mongobitnami-mongodb-1.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017,mongobitnami-mongodb-2.mongobitnami-mongodb-headless.mongodb.svc.cluster.local:27017" --authenticationDatabase admin -u root -p $MONGODB_ROOT_PASSWORDYou will see a running cluster (with arbiter, it is enabled in the chart by default) in the appropriate namespace:

However, such a minimal configuration does not provide you a means to overcome the aforementioned challenges. Therefore, the following tweaks are highly recommended:
- Configure the PDB (it is disabled by default). We want to preserve the cluster even if some of its nodes have been drained. Thus, set the max number of unavailable nodes to 1 (Values.yaml#L562-L571):
...
pdb:
create: true
maxUnavailable: 1
...- Set the requests and limits (Values.yaml#L424-L445):
...
resources:
limits:
memory: 8Gi
requests:
cpu: 4
memory: 4Gi
...On top of that, you can increase the priority of MongoDB pods relative to the rest of the Pods (Values.yaml#L370).
- By default, the chart defines soft anti-affinity rules for the cluster pods. In other words, the scheduler will host MongoDB’s pods on the same nodes only if there is no other choice.
If you have plenty of resources and nodes, it makes sense to set it to “hard” so that two instances cannot run on the same node (Values.yaml#L349):
...
podAntiAffinityPreset: hard
...The Helm chart uses the following algorithm to deploy the cluster:
- Run a StatefulSet with the required number of replicas and two init-containers,
volume-permissionsandauto-discovery. - The
volume-permissionscontainer creates a directory for data and sets permissions for them. - The
auto-discoverycontainer waits until all of the services are ready and saves their addresses toshared_file. The latter is used to transfer configuration data between the init and the app container. - The main container is started with the substituted
command, definedentrypointandrun.shvariables. entrypoint.shis run. What it does is invoke a set of nested Bash scripts and call the functions defined in it.- Finally, MongoDB is initialized using the following function:
mongodb_initialize() {
local persisted=false
info "Initializing MongoDB..."
rm -f "$MONGODB_PID_FILE"
mongodb_copy_mounted_config
mongodb_set_net_conf
mongodb_set_log_conf
mongodb_set_storage_conf
if is_dir_empty "$MONGODB_DATA_DIR/db"; then
info "Deploying MongoDB from scratch..."
ensure_dir_exists "$MONGODB_DATA_DIR/db"
am_i_root && chown -R "$MONGODB_DAEMON_USER" "$MONGODB_DATA_DIR/db"
mongodb_start_bg
mongodb_create_users
if [[ -n "$MONGODB_REPLICA_SET_MODE" ]]; then
if [[ -n "$MONGODB_REPLICA_SET_KEY" ]]; then
mongodb_create_keyfile "$MONGODB_REPLICA_SET_KEY"
mongodb_set_keyfile_conf
fi
mongodb_set_replicasetmode_conf
mongodb_set_listen_all_conf
mongodb_configure_replica_set
fi
mongodb_stop
else
persisted=true
mongodb_set_auth_conf
info "Deploying MongoDB with persisted data..."
if [[ -n "$MONGODB_REPLICA_SET_MODE" ]]; then
if [[ -n "$MONGODB_REPLICA_SET_KEY" ]]; then
mongodb_create_keyfile "$MONGODB_REPLICA_SET_KEY"
mongodb_set_keyfile_conf
fi
if [[ "$MONGODB_REPLICA_SET_MODE" = "dynamic" ]]; then
mongodb_ensure_dynamic_mode_consistency
fi
mongodb_set_replicasetmode_conf
fi
fi
mongodb_set_auth_conf
}2. “Deprecated” chart
By doing a brief search, you can find an old chart in the main Helm repository. Currently, it is listed as “deprecated” (due to the release of Helm 3 — see here to learn more). However, the community still supports it as it is being used by many organizations independently in their repositories (for example, click here for the corresponding repository of the Norwegian UiB University).
This chart cannot run the replica set + arbiter bundle and uses the small, third-party image in containers. Otherwise, it is pretty easy to use and does an excellent job deploying a small-sized cluster.
We had been using it for a long time before it got deprecated on September 10th, 2020. Over that time, there were many changes made to the chart. However, it has retained its basic operation logic. We adapted the chart to our needs, making it as concise as possible by removing unnecessary elements such as templating and functions that are unrelated to our tasks.
The basic configuration is similar to that of the chart above. Note that you will need to set the affinity manually (Values.yaml#L108):
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: mongodb-replicasetIts algorithm is similar to that of the Bitnami chart but is more straightforward (it lacks a script bonanza that its Bitnami counterpart has):
- The
copyconfiginit container copies the configuration from theconfigdb-readonlyConfigMap and the secret’s key to the config directory (anemptyDirvolume that will be mounted to the main container). - The
unguiculus/mongodb-installsecret image copies thepeer-finderexecutable towork-dir. - The
bootstrapinit container runs peer-finder with the/init/on-start.shargument: this script discovers the running nodes of the MongoDB cluster and adds them to the Mongo config file. - The
/init/on-start.shscript runs depending on the configuration passed on to it via environment variables (authentication, adding extra users, generating SSL certificates). Furthermore, it can run the additional custom scripts we need to run before the database starts. - Here is how the list of peers is created:
args:
- -on-start=/init/on-start.sh
- "-service=mongodb"
log "Reading standard input..."
while read -ra line; do
if [[ "${line}" == *"${my_hostname}"* ]]; then
service_name="$line"
fi
peers=("${peers[@]}" "$line")
done- The list of peers is then used to find out the primary/master peers.
- If the peer isn’t the primary one, it is added to the primary group in the cluster.
- The very first instance is initialized; it becomes the master.
- The users with admin privileges are set up.
- The MongoDB process then launches.
3. Official operator
The community edition of the official MongoDB operator for Kubernetes was released in 2020. It makes it easy to deploy, update, and scale a MongoDB cluster. On top of that, the operator is much easier to configure compared to charts.
The downside is that the community edition has limited functionality and does not support extensive customization compared to the charts we just mentioned. It is not surprising, given that there is also an enterprise edition.
The operator’s architecture: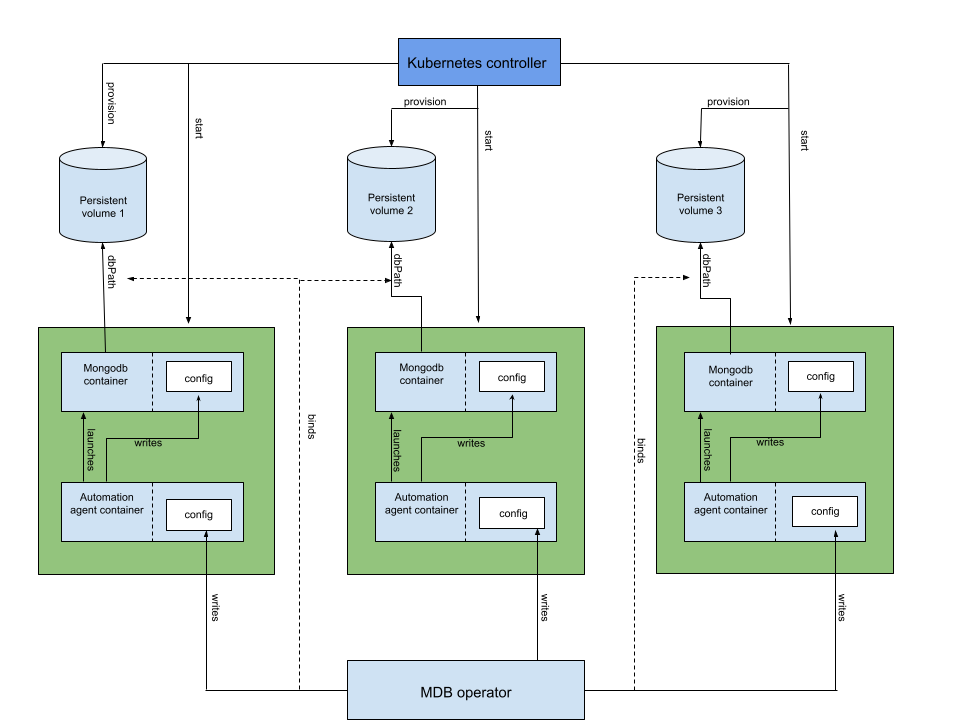
In contrast to standard Helm installation, you will need to install the operator itself and the CRD (CustomResourceDefinition) to create Kubernetes objects.
The deployment process goes as follows:
- The operator creates a StatefulSet containing Pods with MongoDB containers. Every one of them is a member of the Kubernetes ReplicaSet.
- The operator creates a config (and updates it) for the agent’s sidecar container responsible for configuring MongoDB in each Pod. The config is saved to the Kubernetes Secret.
- The operator creates a Pod with one init container and two app containers on it.
- The init container copies the hook’s binary (which checks the MongoDB version) to the shared
emptyDirvolume (to pass it to the app container). - The MongoDB agent’s container manages the main database container. It configures, stops, and restarts the database container and makes changes to the configuration.
- The init container copies the hook’s binary (which checks the MongoDB version) to the shared
- Next, the agent’s container generates a MongoDB config using the configuration defined in the cluster’s Custom Resource.
When it’s all said and done, the entire installation process comes down to this:
---
apiVersion: mongodb.com/v1
kind: MongoDBCommunity
metadata:
name: example-mongodb
spec:
members: 3
type: ReplicaSet
version: "4.2.6"
security:
authentication:
modes: ["SCRAM"]
users:
- name: my-user
db: admin
passwordSecretRef: # reference to the secret below to generate user password
name: my-user-password
roles:
- name: clusterAdmin
db: admin
- name: userAdminAnyDatabase
db: admin
scramCredentialsSecretName: my-scram
# this secret is used to generate the user account
# once it is created, the secret is no longer needed
---
apiVersion: v1
kind: Secret
metadata:
name: my-user-password
type: Opaque
stringData:
password: 58LObjiMpxcjP1sMDWThere are several advantages to the official operator: it can scale the number of replicas in the cluster up and down, and it can perform upgrades (and even downgrades) without downtime. It can also create custom roles and users.
At the same time, in some respects, it is inferior to the two other options: it cannot export metrics to Prometheus, and it can only be run as a replica set (i.e., you cannot create an arbiter). Moreover, this deployment method lacks customization options since almost all parameters are set via the custom agent, which features its own limitations.
The community edition of the operator has very poor documentation at the time of writing. No detailed description of the configuration is available, which leads to numerous issues during debugging or troubleshooting.
As mentioned before, the operator also comes in an enterprise edition. It provides a more extensive set of features, including sharded clusters (in addition to replica set ones), access from outside of the cluster (along with specifying names to use for accessing), additional authentication methods, and so on. And, of course, it boasts more extensive and detailed documentation.
4. Percona Kubernetes Operator for PSMDB
In 2019, Percona introduced its Percona Server for MongoDB (PSMDB) Kubernetes operator. It has almost the same set of features as the official MongoDB Community Kubernetes Operator. The difference is that Percona’s operator also includes options that are only available in the enterprise version of the official operator.
Features of Percona Kubernetes Operator for PSMDB:
- Deploying a MongoDB cluster that supports various Service types: ClusterIP, NodePort, LoadBalancer. (The latter is especially useful for cloud K8s clusters.)
- Horizontal node scaling within a single K8s ReplicaSet.
- Support for sharding and distributing data between different shards within multiple ReplicaSets.
- Managing backups in S3 via the cluster manifest or separate manifests for on-demand backups.
- Adding an arbiter to the configuration.
- Using images from custom repositories in a private environment.
- Automatic and semi-automatic MongoDB version updates in the cluster Pods.
Below is the minimum configuration to fire up a MongoDB cluster using Percona Kubernetes Operator:
apiVersion: psmdb.percona.com/v1-7-0
kind: PerconaServerMongoDB
metadata:
name: mongodb
spec:
crVersion: 1.7.0
image: percona/percona-server-mongodb:4.4.3-5
imagePullPolicy: IfNotPresent
allowUnsafeConfigurations: true
updateStrategy: RollingUpdate
secrets:
users: my-secrets
pmm:
enabled: false
replsets:
- name: rs0
size: 1
affinity:
antiAffinityTopologyKey: "kubernetes.io/hostname"
podDisruptionBudget:
maxUnavailable: 1
expose:
enabled: false
exposeType: LoadBalancer
volumeSpec:
persistentVolumeClaim:
storageClassName: rbd # specifying your storage class is required
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 30Gi
resources:
limits:
memory: 2Gi
requests:
cpu: 300m
memory: 2Gi
arbiter:
enabled: false
sharding:
enabled: false
mongod:
net:
port: 27017
hostPort: 0
security:
redactClientLogData: false
enableEncryption: false
setParameter:
ttlMonitorSleepSecs: 60
wiredTigerConcurrentReadTransactions: 128
wiredTigerConcurrentWriteTransactions: 128
storage:
engine: wiredTiger
inMemory:
engineConfig:
inMemorySizeRatio: 0.9
wiredTiger:
engineConfig:
cacheSizeRatio: 0.5
directoryForIndexes: false
journalCompressor: snappy
collectionConfig:
blockCompressor: snappy
indexConfig:
prefixCompression: true
operationProfiling:
mode: slowOp
slowOpThresholdMs: 100
rateLimit: 100
backup:
enabled: falseapiVersion: v1
stringData:
MONGODB_BACKUP_PASSWORD: backupPass
MONGODB_BACKUP_USER: backup
MONGODB_CLUSTER_ADMIN_PASSWORD: clusterAdmin
MONGODB_CLUSTER_ADMIN_USER: clusterAdmin
MONGODB_CLUSTER_MONITOR_PASSWORD: clusterMonitor
MONGODB_CLUSTER_MONITOR_USER: clusterMonitor
MONGODB_USER_ADMIN_PASSWORD: userAdmin
MONGODB_USER_ADMIN_USER: userAdmin
PMM_SERVER_PASSWORD: admin
PMM_SERVER_USER: admin
kind: Secret
metadata:
name: mongodb-secrets
type: OpaqueThis configuration deploys a single replica set. The operator does not provide a standalone mode, but you can run a replica set with a single node.
Unlike the official MongoDB Operator that manages the cluster through sidecar containers with running agents, the Percona Kubernetes Operator does it directly from its Pod. The operator makes the necessary requests to the K8s API inside the cluster, configuring MongoDB and Pods according to the Percona Server MongoDB custom resource manifest.
Personally, we use the minimum configuration listed above. However, we have not yet tested it in production.
Sharding
Percona’s documentation suggests that creating a new shard is not supposed to be complicated. All you need to do is to add a new replica set with a different name and fill in parameters of config servers and mongos instances in the sharding section:
sharding:
enabled: true
configsvrReplSet:
size: 3
affinity:
antiAffinityTopologyKey: "kubernetes.io/hostname"
podDisruptionBudget:
maxUnavailable: 1
resources:
limits:
cpu: "300m"
memory: "0.5G"
requests:
cpu: "300m"
memory: "0.5G"
volumeSpec:
persistentVolumeClaim:
resources:
requests:
storage: 3Gi
mongos:
size: 3
affinity:
antiAffinityTopologyKey: "kubernetes.io/hostname"
podDisruptionBudget:
maxUnavailable: 1
resources:
limits:
cpu: "300m"
memory: "0.5G"
requests:
cpu: "300m"
memory: "0.5G"
expose:
exposeType: ClusterIPThe operator will then create a new shard and add config Pods as well as instances that route queries and write operations to the shards:
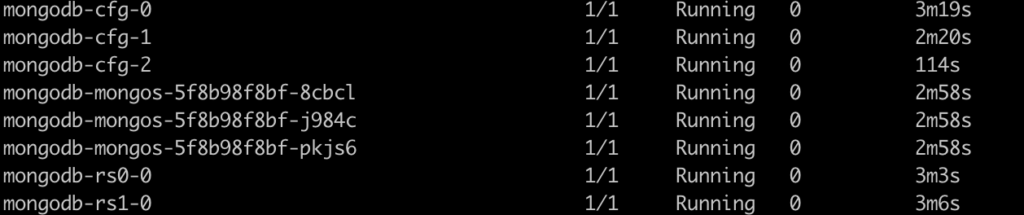
On top of that, it will switch the endpoint from a specific ReplicaSet to the mongos interface:
kubectl get psmdb

Backups
In our case, we did not experiment with backup management since there is a unified external backup solution in our company. The general PSMDB operator approach is to use some “nearby” minio instance for dumping data and retrieving finished files from it in a centralized fashion.
For this, add credentials to the backup section and specify the backup schedule:
backup:
enabled: true
restartOnFailure: true
image: percona/percona-server-mongodb-operator:1.7.0-backup
serviceAccountName: percona-server-mongodb-operator
storages:
minio:
type: s3
s3:
bucket: mongo-backup
region: us-east-1
credentialsSecret: mongodb-backup-minio
endpointUrl: http://minio:9000/minio/
tasks:
- name: daily-s3-us-west
enabled: true
schedule: "0 0 * * *"
keep: 3
storageName: s3-us-west
compressionType: gzipapiVersion: v1
kind: Secret
metadata:
name: mongodb-backup-minio
type: Opaque
data:
AWS_ACCESS_KEY_ID: secret123
AWS_SECRET_ACCESS_KEY: access123Unique features
- Maintenance mode. The operator can put the cluster into maintenance mode by gracefully stopping it beforehand:
spec:
.......
pause: trueThis parameter instructs the operator to stop the cluster and delete running Pods until they need to be started again.
- Update strategies. The operator automatically updates the cluster by adhering to the selected strategy:
updateStrategy: SmartUpdate
upgradeOptions:
versionServiceEndpoint: https://check.percona.com
apply: recommended
schedule: "0 2 * * *"The PSMDB Operator queries a special Version Service server at cron-scheduled times to obtain fresh information about version numbers and valid image paths. You can select the desired strategy by setting the apply field to one of the following values:
- the most recent version of Percona Server for MongoDB (
recommendedas in the example above); - the most recent recommended version while preserving the specific major MongoDB version (
4.4-recommended,4.2-recommended, etc.); - the most recent version (
latest); - same as above while preserving the specific major MongoDB version (
4.4-latest, etc.).
You also disable this feature using never or disabled.
By default, the FeatureCompatibilityVersion (FCV) parameter isn’t set to match the new version, thus disabling the backward-incompatible features after the major version upgrade. However, you can change this behavior by enabling the upgradeOptions.setFCV flag.
Note that in addition to the SmartUpdate strategy, there is also a semi-manual update strategy (RollingUpdate) and a manual one (OnDelete). In the first case, Pods will be redeployed one by one. In the second case, you will need to delete the Pods created by the operator to trigger the version update manually.
Conclusion
The scalable database in Kubernetes allows you to unify infrastructure, adjust it to a specific environment, and manage application resources flexibly. However, it requires careful planning and attention to detail. Otherwise, it can become a major headache (the same is true even if Kubernetes isn’t involved).
The different options for running MongoDB all feature their own advantages. Charts are easily adaptable to specific needs, but you will encounter problems when upgrading MongoDB or adding new nodes – some procedures with the cluster you will have to do manually. In that sense, the method involving the operator is a clear winner. However, there are other aspects in which it is inferior to charts (particularly, if we speak about the official community edition). Furthermore, neither of the options can run hidden replicas out of the box.
It is worth noting that MongoDB managed services are also available. However, we choose not to lock into specific providers in our practice, preferring “pure” Kubernetes alternatives instead.

Thanks for the article. I first tried the Official operator community edition. It was working well, until I figured out it is impossible to adjust the resources limits. I even checked their source code out to confirm. Patching the STS is an insta-revert. There is no way to adjust the resource limit. It was a huge negative hit for me and I am sharing here, that as of v0.7.8, it does not allow you to override the resource limits for Mongo. Please notice that it allows you to set the resource limit for the operator itself, however for the STS you have no options.
Thanks for this amazing article!